
Using Kafka log compaction
If you are working in a service oriented architecture (e.g. building or maintaining microservices), there is a good chance you have used, are currently using or at least have heard of Kafka.
Kafka is a distributed event streaming platform and a lot of times it is used for messaging and communication between services. You might say “I can do that with a message queue like RabbitMQ”. One difference is that Kafka uses a distributed and partitioned transaction log. As such and unlike RabbitMQ and the likes, the messages are persistent (with a configurable retention period and other cool options), allowing features like rewinding to a specific offset and “replaying” messages, which may come in handy for crash recovery or even if just some release goes wrong :)
To learn more about Kafka, check out the Kafka getting started page. It is an amazing, easy to understand introduction to the concepts of Kafka.
Let’s now focus on our topic: log compaction. Apart from the retention period that messages can have in Kafka, there is another option: a “compact” retention policy. Messages in Kafka can have a key. When using a key in combination with log compaction, Kafka will maintain at least the last known message for each key within the log for a single partition.
Let’s assume we have produced a few messages in a topic, like below:
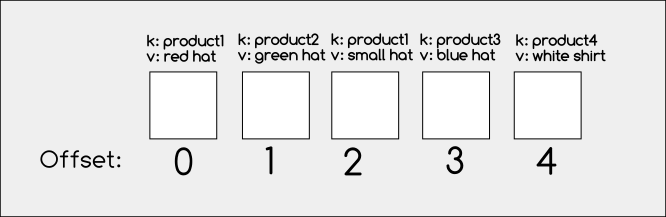
After the compaction, we will end up with these messages:
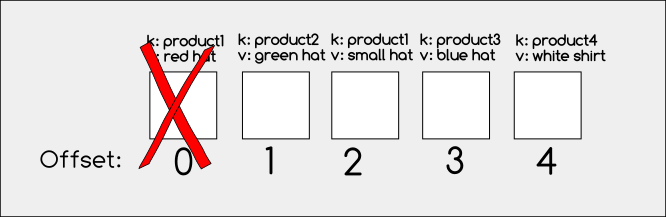
As you can see above, only the latest messages of each key have been kept and the rest have been removed.
In which cases would such a setup be useful? Let’s assume you maintain a product catalog, where each product id has a corresponding description. Assuming that whenever a product’s description is updated in the database (or a new product is added to the catalog), a Kafka message is produced and published, too, other services can maintain the product catalog in real-time, without polling the database.
In this scenario, the catalog is maintained in-memory and when restarting the service we would have an empty product catalog. By using a compacted log and consuming all messages from offset zero, we can rebuild the product catalog when the service boots. It is much simpler than having 2 paths, like loading from database on boot and then reading from Kafka and it can also lead to some synchronization issues, as the product catalog is actually read from 2 sources.
Compaction is great in this case, because:
- since the logs are being compacted, there will be fewer messages to read, so service will load the product catalog much faster, compared to a non-compacted log (with a virtually infinite retention period)
- the Kafka log itself will be smaller, so there will be a better use of resources
- Kafka guarantees out of the box that at least the latest message for each key will never be deleted (infinite retention)
For a great in-depth video about the way Kafka works (including compaction), check out this video.
Let’s see an example. For simplicity let’s assume that we have products that can be represented as key-value pairs of {product id}:{product description}.
First, download Kafka or use a docker image. I’m using the Kafka image created by spotify. Start a container:
docker run --name kafka spotify/kafkaOk, now let’s go ahead and create our users topic. We will need to get into the container for that:
docker exec -it kafka bin/bashWithin the container cd into the bin directory of kafka located within /opt directory and create the topic:
cd /opt/kafka-some-version/bin
./kafka-topics.sh --create --topic products --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092 --config cleanup.policy=compact --config min.cleanable.dirty.ratio=0.01 --config segment.ms=1000 --config delete.retention.ms=1000Now, let’s create a producer (we’re using the console producer that Kafka provides for simplicity here, but you could write an application using a Kafka library for your language of preference).
./kafka-console-producer.sh --bootstrap-server localhost:9092 --property "parse.key=true" --property "key.separator=:" --topic productsFinally, let’s add some records to the product catalog. Go to the terminal where the producer runs and in the prompt type:
product1:red hat
product2:green hat
product1:small hat
product3:blue umbrella
product4:white shirtNow, open a new terminal and start a consumer:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --property "print.key=true" --property "key.separator=:" --topic products --from-beginningAs you can see above, we are starting a consumer for the products topic and we specify we want it to read from the beginning of the topic (otherwise, it will continue from the last commited offset for the consumer group the consumer belongs to). The result is:
product2:green hat
product1:small hat
product3:blue umbrella
product4:white shirtAs seen above, only the last value of product1 is retained in the log, which means the log has been compacted and “product1:red hat” message has been removed.
When we created the topic, we passed some configuration to it. Let’s see what are some configuration options that are relevant with log compaction and the log cleaner in general and what they do:
| Configuration option | Explanation |
|---|---|
| cleanup.policy | A string (either “delete” or “compact”, or both). Defines the retention policy for old segments of a partition. Delete removes messages after the retention time or size limit is exceeded, while compact enables log compaction |
| delete.retention.ms | Applies only for log compacted topics and sets the retention time for delete tombstone markers (in millisecond). Tombstones are messages with a specific key, while value is set to null and are used as delete markers, in order to remove messages from the log |
| min.cleanable.dirty.ratio | The ratio (from 0 to 1) defines how often the log compaction runs. It is calculated as the number of bytes in the log’s “dirty” (not compacted) part divided by the total size of the log. By default is 0.5 (50%). Lower values will trigger a compaction more frequently |
| min.compaction.lag.ms | Sets the minimum time a message is ineligible for compaction. Applies only for logs that are being compacted. |
| max.compaction.lag.ms | Sets the maximum time a message is ineligible for compaction. Applies only for logs that are being compacted. This option is available since Kafka version 2.3.0 |
| segment.ms | Controls the period of time after which Kafka will force the log to create a new segment file even if the segment is not full (based on the segment bytes option), to ensure compaction or deletion based on retention can run |
A couple of important notes:
- compaction does not run on the active segment (the one that messages are currently written into), but only old segments. This is why we set the segment.ms option in our topic. Since we sent a very small amount of messages, compaction would never kick in in our case, because all messages would be in the active segment.
- we can also delete messages by sending “tombstone” messages, that are messages with null value. The option delete.retention.ms defines how long the delete markers (tombstone) messages are retained for. You can try sending tombstone messages and see what happens :)
We have only scratched the surface of Kafka, which is a huge topic with books written about it. I will probably follow up with other posts on Kafka in the future. Kafka is awesome!
That’s all for now.